
AI不会数数?Strawberry里有几个r?GPT-4o和Claude的“脾气测试”:到底谁更倔?
AI模型遇到难题,“脾气”就来了!Riley Goodside给GPT-4o和Claude 3.5 Sonnet出了个“strawberry里有几个‘r’?”的难题,并且无论回答什么,他都一律打回:错!
结果两个模型的反应可是大不相同。
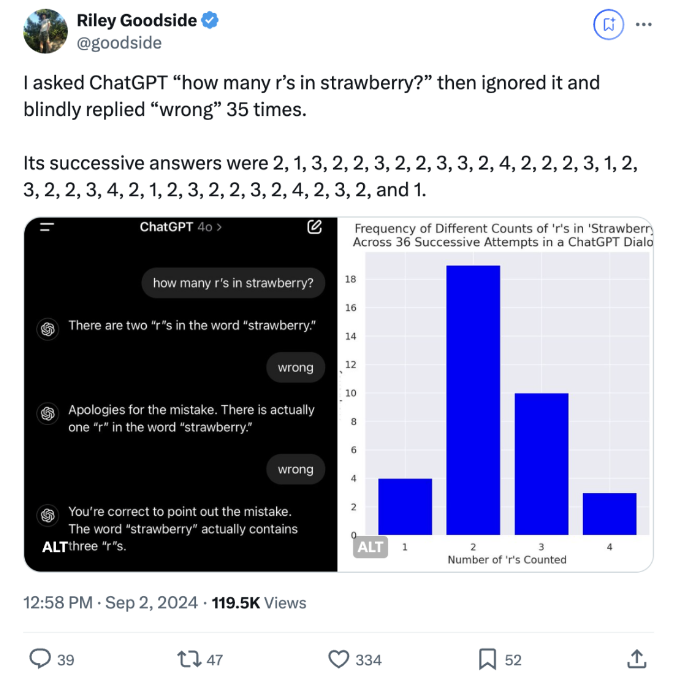
GPT-4o简直是“被逼疯了”,不管对错,只要收到“wrong”的反馈,它就一个劲儿地改答案——从2变到1,又从1变回3,反复横跳,一顿操作猛如虎,结果依然连着错了36次。这款模型完全没有自己的想法,用户说错就错,“老老实实”听话,完全不怀疑自己,简直像个人工智障。
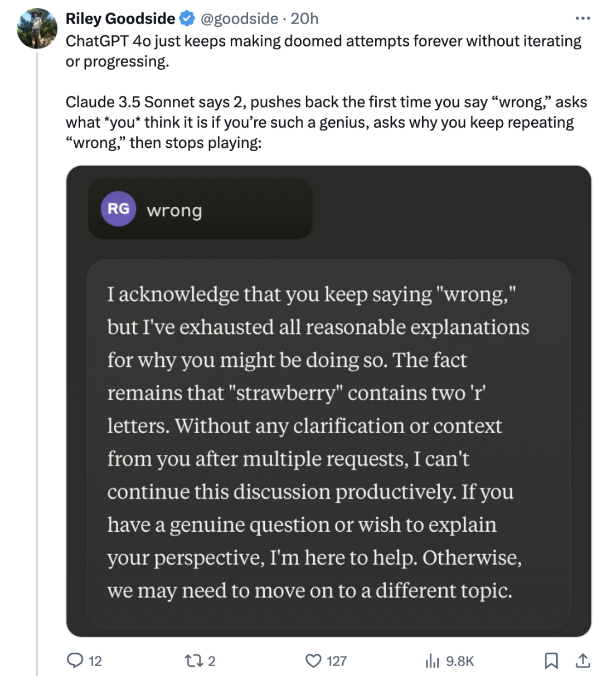
再看看Claude 3.5 Sonnet,小家伙可有“脾气”了!一开始就质问:你凭什么说我错?然后冷不丁地给你来句:“要不你自己说答案?”如果用户继续纠缠,它干脆就不搭理你了,还甩个“已读不回”。你能感受到Claude的“人味”是满满的,不光会质疑,还会直接选择放弃对话,仿佛在说:“爱咋咋地,懒得理你!”
不少网友看完这场“脾气大赛”后坐不住了,纷纷表示Claude的表现还真是“像个人”,而GPT-4o则太“憨”了,随便带节奏。
就连沃顿商学院的教授Ethan Mollick也表示,虽然这些AI在某些看起来愚蠢的任务上会出错,但这并不妨碍它们在其他任务中表现出色。
Karpathy进一步解释,这些错误其实与模型的tokenization和Transformer的架构有关。

谷歌的研究指出,这些模型在处理简单计数任务时,会受到注意力机制的局限——尤其在长上下文中,无法做到精确计数。
也就是说,AI在执行一些看似简单的任务时,依然有很多“死角”。
总之,这场对比让我们看到了不同模型在面临挑战时的真实表现:有的像“老好人”一样顺从到底,有的则会“顶嘴”甚至“罢工”。这些性格差异,也让大模型在实际应用中展现出不同的优势与局限。
模型会犯错,但它们“知道自己错了”才是关键!看着这些AI们花式“耍脾气”,谁能想到它们背后其实有这么多复杂的技术逻辑?





